Women are oppressed, coeds are elected, and men are swindled: A brief intro into text analysis using AUC's student newspaper

My next foray into digital humanities (you can read about mapping the nationalities of AUC students here) involves the venerable students newspaper the Caravan (aka the AUC Review, Campus Caravan, and Caravan Weekly). The first issue was published in 1925 and it is still going strong today. Currently, we have issues up to 1996 available in our Digital Library though some years are missing (either because of scanning issues or we don’t have them at all, in the latter case please let us know if you have copies). The Caravan has been bilingual through most of its history, though this project will focus on the English issues only.
With the excellent work done by the digitization lab we have over 4,000 English pages scanned, and through ABBYY FineReader we’ve generated text files for each page, creating a corpus to explore. Unfortunately for some pages the text recognition leaves a lot to be desired; often this is caused by poor quality printing or ABBYY being confused.
 |
| Not great, Bob. |
I believe we have a robust quality control system, but with some many pages (and other projects) much of the process is automated and mistakes slip through. Luckily with such a large corpus individual errors hopefully won’t have much of an effect on our results. However, for a serious academic study data cleanup will be necessary, which would be a real time suck.

The software used to analyze our corpus is AntConc, which is a powerful tool that also has great tutorials and support to make learning easy (and fun!). I followed The Programming Historian’s guide with Caravan issues instead of the text files they supplied. Since the step-by-step process is written up more competently than I could, I will not be getting into the nitty-gritty of loading files and massaging data.
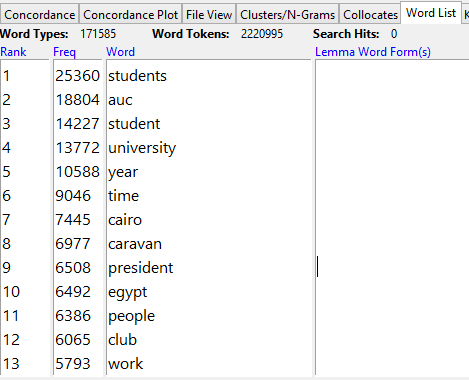
After combining individual text files into one file for each academic year, I fired up AntConc to discover the most common words to appear from 1925 to 1996. With much fanfare, AntConc spat out the following data:

This was not entirely useful, so I applied a stopwords list, which removes whatever words you would like. This particular list removed common words, including pronouns, though it could be interesting to see if budding journalists’ use of “I” or “me” changed over time. Alas, another project. The new and improved most word frequency list is a bit more descriptive and provides a better picture of what Caravan covered, though nothing too earth-shattering.
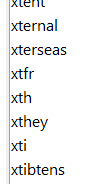
Scrolling down to less frequent words we find some recognition errors :(
and some Arabic text that is likely in a misnamed file (in our system the language is indicated in the file name).

By clicking on individual words in the master, we can explore when and how they’ve been used. For example, we can see all 2,292 times “women” appears in our corpus with the “concordance” tool:

Collocation is another analytical tool which shows how often words appear together, which can be useful for comparison (e.g. what words are around “men” and “women”). I am not very knowledgeable about the best strategies for this, such as how many words should AntConc read to the left and right for the best results.

As with anything, fine tuning is necessary and after seeing how text recognition issues really impacted the results with “women” and it's collocation terms. For example, since “women” appears next to the only time “tiandball” (a traditional AUC sport that is not well known outside campus) is used in eighty years of Caravan text the collocation score is going to be very high.

Since the results for the entire corpus were dominated by incorrectly recognized words, for the following example I set the minimum collocation frequency to four, hoping that would weed out poor text recognized “words” that only appear once in the entire corpus. I think my decision resulted in a much more interesting word list than the previous garbled mess. Having said that, as a newcomer to text analysis I chose four more-or-less randomly, there is likely a more scientific way to determine the minimum frequency count.
 |
| "Trojan" is because AUC put on a production of Trojan Women. |
For comparison here is the list of words collocated with “coed,” a term that was commonly used in the fifties:

With the plot chart we can see the decline in the use of “coed”.
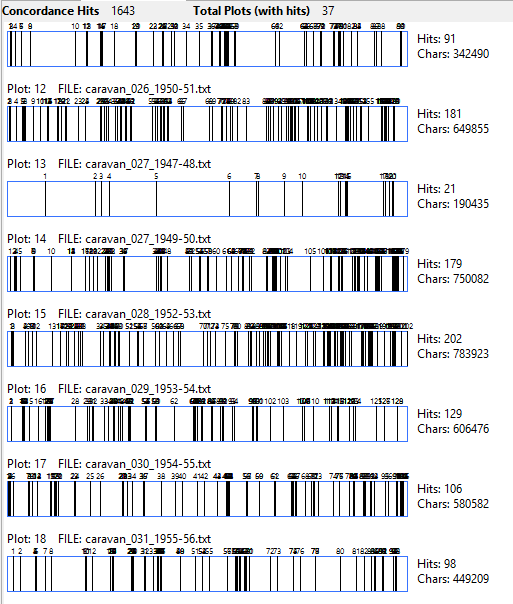

Lastly, we’ll see what terms most often appeared with “men” across the entire corpus:

There is a lot to unpack here; "swindled" appears because the same joke ran twice in the Caravan (1975 and 1983) which statistically pushed it to the top.
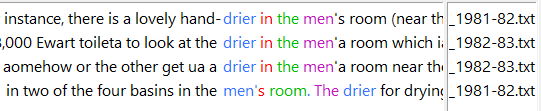
 Amusingly, “drier” refers to a hand-drier in the men’s bathroom, which apparently was a big deal in the early 1980s.
Amusingly, “drier” refers to a hand-drier in the men’s bathroom, which apparently was a big deal in the early 1980s.
The last feature I’ll discuss is the Keyword tool, which compares selected text files with the entire corpus for comparison. This could be two separate corpora, but for this example we’ll compare Caravans during World War II with the entire corpus. “The Programming Historian” has the following description of keywords from the creator of AntConc’s documentation:
> Keyness: this is the frequency of a word in the text when compared with its frequency in a reference corpus, “such that the statistical probability as computed by an appropriate procedure is smaller than or equal to a p value specified by the user.” – taken from here.) For those interested in the statistical details, see the section on keyness on p7 of Laurence Anthony’s readme file.
Perhaps surprisingly, while “war” is one of the top keywords the list is dominated by names of AUC administrators. Further research would be needed to determine whether “war” “Germany” etc. were not discussed in the Caravan during the war or if war was commonly written about throughout the paper’s history.
 |
| Lincoln College was AUC’s preparatory school and the Maskers were a theater club which was a big deal on campus from the 1920s until the 1970s. |
The results for the ‘90s are a bit more satisfactory and show how new topics were being covered (e.g. computer, security, and perhaps “asst” is a sign of the rise of administrators in universities as well):
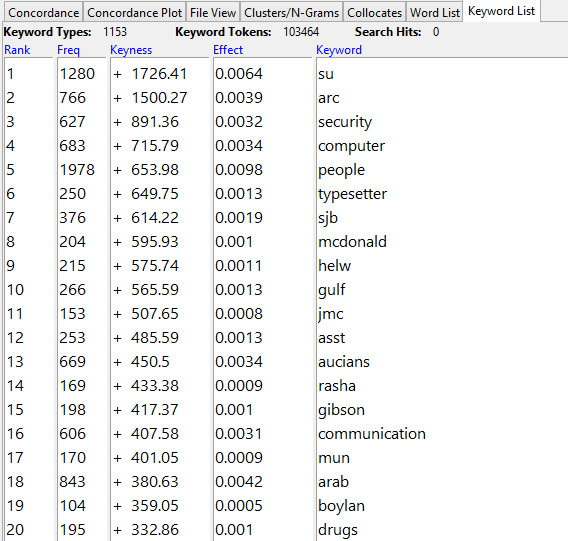
We can also directly compare texts from different years or decades; an interesting possible change in the practice of journalism at AUC was discovered when comparing the 1980s against the 1950s (without stopwords, otherwise "said" doesn't appear).

At first I thought “said” might have been a proper name, but it turns out it appears because journalists begin directly quoting people with much greater frequency. To wit:

Of course a researcher reading through the back issues may notice the shift in how information is reported, but text analysis makes the process easier.
Finally, I ran five Caravan issues from 2016-17 against the entire 1920s-1990s corpus, and the results aren't particularly surprising (except for bagels). An obviously interesting study would be the Caravan in 2010 versus 2012, though we don't have those issues yet.

This has been a very brief foray into text analysis, but I think there are a lot of interesting questions that can be asked, and inshallah answered, about AUC and Egypt, using the Caravan as a corpus (and what better time to ask them than during our centennial year?).
- How has the language used (and presumably taught) at AUC changed over time?
- What events have--or have not--been covered?
- How has the way in which different demographic groups are represented in the Caravan changed over time?
- What might a comparison between the Caravan and the American University in Beirut’s student newspaper show? What about other publications at AUC, such as The Insider?
To me, the holy grail of Caravan projects would be a comparison of the English and Arabic editions since for several decades they were independent, and may cover different topics, or the same topic quite differently.
Open access to information is something we value in the RBSCL and so the text files are available in our institutional repository, though please share any results with us.
-- Ryder
-- Ryder
Resources
Anthony Laurence's Youtube tutorials: https://www.youtube.com/watch?v=O3ukHC3fyuc
Heather Froehlich's tutorial at The Programming Historian: https://programminghistorian.org/en/lessons/corpus-analysis-with-antconc
The Grammar Lab's AntConc walkthrough: http://www.thegrammarlab.com/?nor-portfolio=antconc-walk-through
Comments
Post a Comment